データ活用の裾野を広げる:mcp-snowflake-serverの導入とデータ分析の変化への期待

皆さん、こんにちは。株式会社カオナビでデータ収集〜活用を推進するチームを率いています、本江 雄人(@Yuto_Hongo)です。
普段は、データ基盤の構築・運用から、製品利用実績・社内の営業活動データの活用推進、加えて「人的資本データnavi」でのAIを活用した有価証券報告書データ収集・メディア運用など担当しています。
今回は、データを活用していくため「mcp-snowflake-server」の導入について、その背景から利用してみての感想までをお話しします。データ活用の民主化に悩む方、mcp-snowflake-serverに興味がある方に少しでも参考になれば嬉しいです。
https://github.com/isaacwasserman/mcp-snowflake-server
:::note info
本記事のサマリ mcp-snowflake-server に関して
- ローカルで動作し、Snowflakeのユーザー・ロール準拠の権限管理となる
- SQLを書けない層へデータ接点を増やし、データのさらなる民主化が期待できる
- データ構造が整っていないとAIもデータを理解ができなかったため、データモデリングなどデータ整備はAI時代にも必要で有り続けるのでは?
:::
背景:推し進めてきたデータサイロの解消
昨年のDevOpsDays Tokyo 2024で「カオナビの利用実績をアウトカムへつなげる旅」と題して発表させていただいたのですが、各部署でデータが閉じてしまっていたり、容易にアクセスできないといった課題(というより、とてももったいない状況)がありました。
機密レベルを考慮した社内のさまざまなデータを1箇所に集約することで、社内の人がデータにアクセスできる環境を整えてきました。その結果、社内でのデータ基盤(Snowflake)の利用ユーザー数は社内300名弱と増え、定点観測用のダッシュボードの閲覧・利用などに関してはかなり成熟してきました。
https://speakerdeck.com/kaonavi/example-of-data-management-startup-in-kaonavi
見えてきた新たな壁: 組織の裾野までは広がらない活用
組織全体に対してデータの活用を推進したことで活用されているダッシュボード等は増えてきたのですが、段々と新たな課題がでてくるようになりました
- 現場のデータに対する関心が増えるほどに分析軸などをカスタマイズしたデータを見るニーズが高まるが、SQLを書いたりExcelの集計を使いこなせる人材は限られている
- データから「見解」を引き出したり、新しい「インサイト」を見出したりするのも一定の練度が必要とされる
そんな課題が新たにでてきてはいるものの、実は当社にはそれをフォローしてくれるツール自体は存在しているんです。
ナービィというLLMチャットボットが導入されており、SQLの作成補助やBIのスクリーンショットから見解を得るための壁打ちなどにも活用できる環境にはありました。
社内でプロンプトの紹介等を行う勉強会などを開催もしました。

しかしながら、複数のインターフェースをまたいでAIとツールを組み合わせて効果的に活用できる人はまだまだ少ないという現実がありました。
きっかけと出会い:mcp-snowflake-serverとデータエンジニアの先人との会話
そんな中、Anthropicの公式リポジトリで「mcp-snowflake-server」というコミュニティサーバーが紹介されているのを社内のtimesで知りました。それをきっかけに興味を持ち、mcp-snowflake-serverの導入を検討することになりました。
https://github.com/modelcontextprotocol/servers
導入してみたかった理由は主に以下の2点です
- Text to SQLの実現し、データに触れてもらいやすい機会を増やしたかった
LLM×データ基盤のような社内勉強会などを開催してもなかなかデータの深い活用まで推進するのが難しいといった中で、自然言語でSQLを発行しデータの集計作業や見解出しができるなら、SQLを知らない人でもデータを活用する機会が増えると感じました。これによってデータの民主化・活用がさらに進むと思いました。 2. 参加した社外勉強会で「BIはもっと広く捉えるべき。LLMを使うのが前提になるだろう」という会話 「BIイケてないよね」と社内で要望がでていて、あまり個人的にピンときておらずモヤモヤしていたある日、データエンジニアリングを長年実施している先人たちと議論する機会がありました。そこで会話をしていたところ「今のBIがイケているかどうか以前に、集計結果を表示するインターフェースはもっと広く考えるべきだ。これからはLLMを使うことが前提になっていく。」という会話をしたことで、よりmcpを試してみたいと感じました。
弊社内の正式な手続きを通し、さっそく利用に向けた準備を始めることにしました。
導入合意への作戦:法務・情報セキュリティ部門との対話準備
法務・情報セキュリティ部門との協議に向けて、最も重要だったのはセキュリティ・権限の説明です。
「現状ブラウザから利用できているSnowflakeと同じ挙動」である図を準備しておけば、関係部署と会話がスムーズになるのでは? と考えました。
以下の1枚のスライドを準備して、手続きを進める実施しました
- 接続環境:ネットワーク制限、社内ツールアカウント管理ポリシー
- 権限管理:Snowflake内アカウント管理ポリシー、データ操作権限
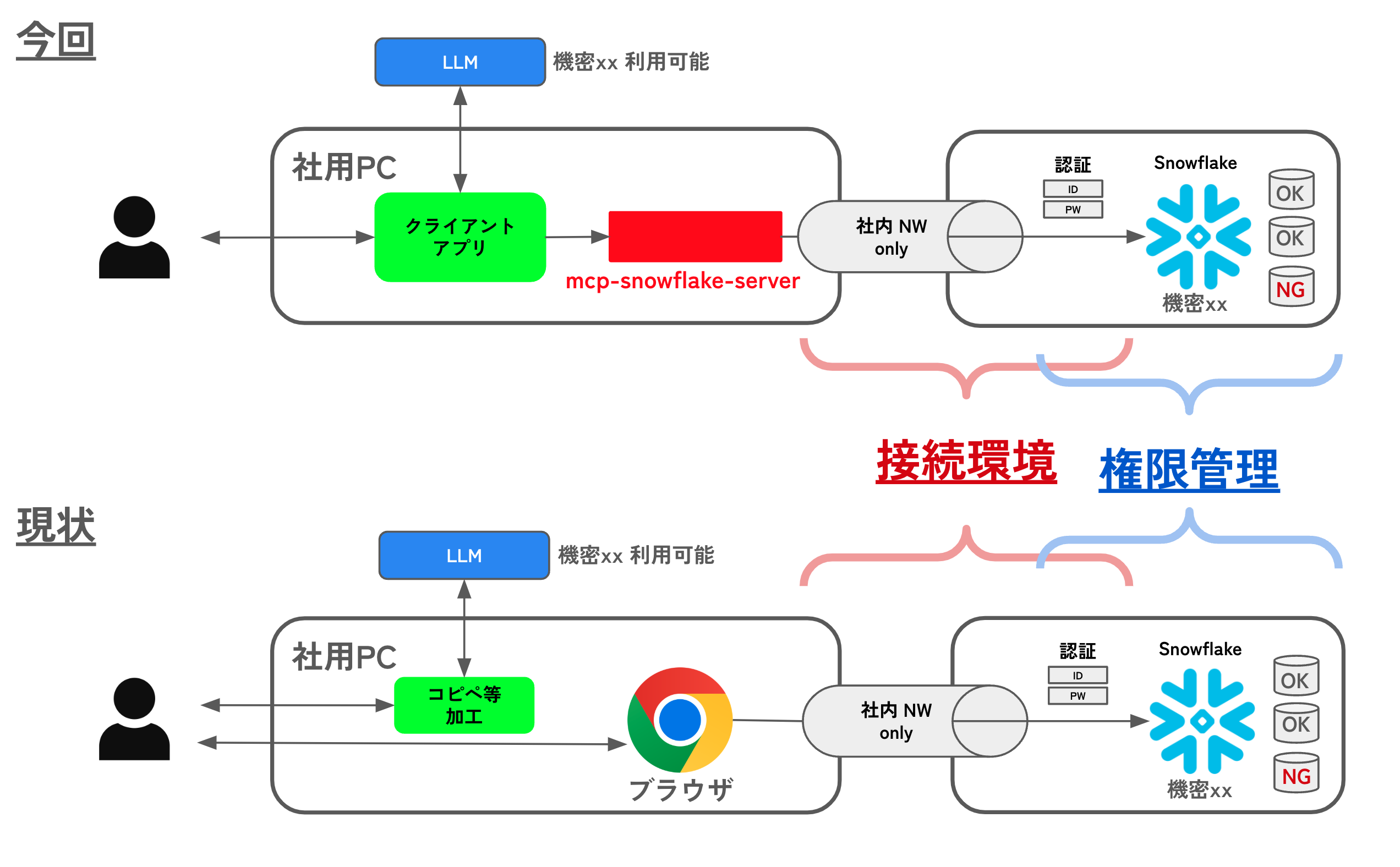
導入のための検証:接続環境・権限管理
社内ネットワーク制限の確認
社外ネットワークからアクセスした場合は以下のようなエラーが表示されることを確認しました。(LLMはしっかりエラー内容も答えてくれますね。)
申し訳ありません。現在、Snowflakeへの接続ができていないようです。エラーメッセージによると、IPアドレスまたはトークンでのアクセスが制限されているため、Snowflakeデータベースの情報を取得できません。ログイン認証動作も確認
認証に関しては、"--authenticator","externalbrowser" というオプションを利用し、ブラウザにてログインする形としています。
弊社で利用しているSSOのログイン画面がでてくるため、そこでログインが完了すると疎通できるといったわけです。
Your identity was confirmed and propagated to Snowflake PythonSnowpark. You can close this window now and go back where you started from.Snowflake内の権限管理
指定したロールでみれる範囲でのみデータ参照となっており、ログインユーザー・ロールに紐づいた参照権限となっておりました。
(ちなみにセカンダリロールは効いてました。強い他権限持ってる方でセカンダリロール有効の環境下では動作はセカンダリロールで参照できる範囲に拡大します)
実行:社内でMCPのデモしてみた
もろもろ検証を終え、いろんなユースケースを試してみることとなりました
デモ:Snowflake内にあるサンプルデータ
あたり前のことを言うんですけど、本当に 「自然言語で指示をすることで、データをいろいろと勝手に探索してくれる」という体験に驚きです!
(以下サンプルは1歩1歩指示出ししてますが、どんなデータが入っているか知っていれば、もっと最初から具体的な指示出ししても問題ないです)
① サンプルデータの中がわからないので雑に聞いてみる (schemas,tables)

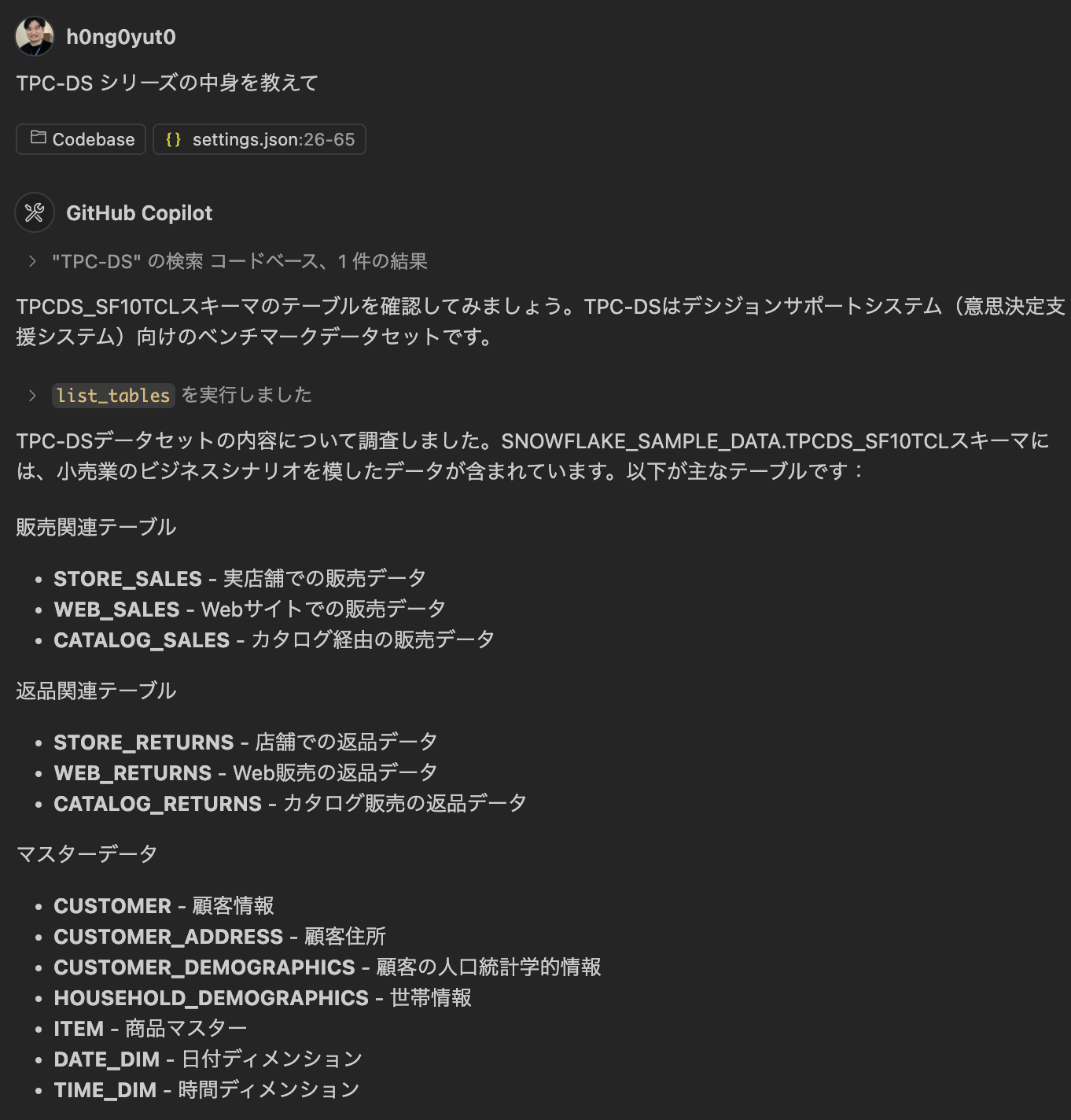
② 集計したい内容を指示出ししてみる

(中略…ずーっとAIが「あーだ」「こーだ」してます!)

失敗事例:整っていないデータに対しての問い合わせは、AIが途中停止
(会社の生のデータなのでお見せはできないんですが…)
元データの構造も同期後のデータ構造もモデリングが追いついていないデータが一部存在しているんですが、あまりに整っていないデータ構造の情報は、AIに分析をお任せしても結果まで辿り着くことができない事例もありました。 (xxxxは検索した内容)
しかし、これらのテーブルでコード検索を行いましたが、現在の検索条件では直接的なxxxxの記録を見つけることができませんでした。データの構造自体が複雑怪奇だと、AIも適切に処理できないことがわかりました。
そういった意味でも、データモデリング(ないし元データ構造の見直しなど)に関してはこれからも重要な業務であり続けるなと感じました。
まとめ:mcp-snowflake-server
挙動
- ローカルで動作する
- Snowflakeで設定したユーザーのログイン方法であったり、ロールに準拠した参照権限で利用することができる
期待すること
- 集計スキルや時間の不足でデータ活用ができていなかった層が気軽にデータに触れられるようなることで、データ民主化に寄与すること
- BIで0からインサイトを考える代わりにAIが見解も出してくれるため、インサイトを見出す時間効率と質の両方を向上できること
懸念されること
- データの構造自体が複雑怪奇だと、AIも適切に処理できない
→ MCPという仕組みによって各データを直接データソースにアクセスできるようになるのが、データモデリングの重要性は変わらず、データエンジニアリングの業務はAI時代にも重要な業務であり続けるのでは?
妄想:データ活用×LLMの未来について
mcp-snowflake-serverの体験を通じて、データ活用×LLMの未来について思うこと
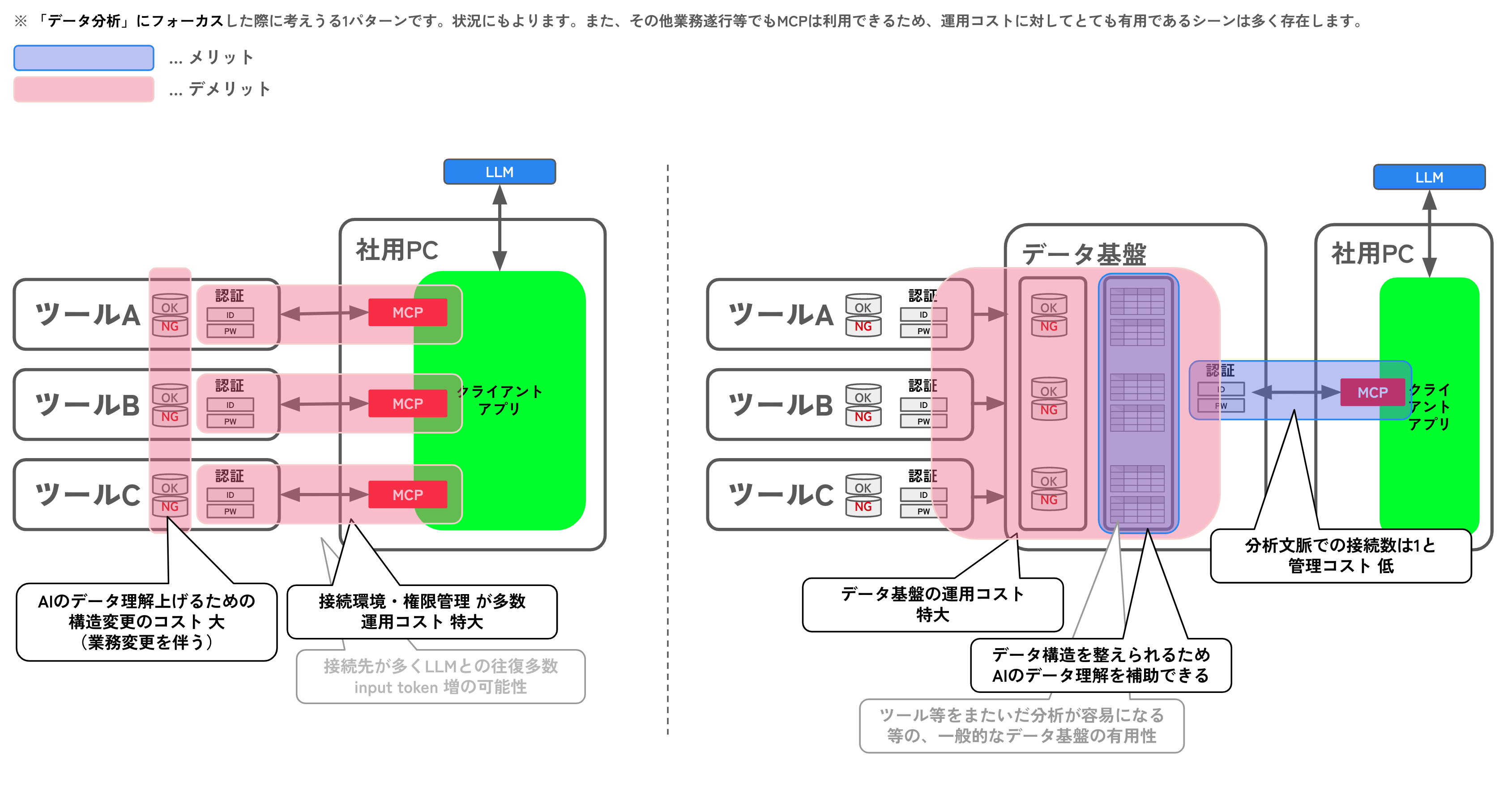
1.MCPの仕組みで直接データ取得できるようになり、データエンジニアリング業・データ3層の整備が廃業なるか? → 多分ならない
前提として、データエンジニアリング・データ基盤の運用でのベタな話としてデータ3層というものがあり、以下のような処理を行いデータ活用しやすい状態を維持するという話があります。
- 「データを持ってきたものを貯める」
- 「データを加工する」
- 「データを特定用途で使いやすい形にする」
https://book.st-hakky.com/data-platform/data-layer/
今回ご紹介したMCPが登場したことにより、 各種データソースとAIエージェントが直接連携し、集計や分析が行われる「データ0層」(?)の時代が来るかもしれません。
しかし、データモデリングを整えるパイプラインが不要になるように見えますが、以下理由でデータエンジニアリングは衰退しないと考えます
- データ自体が整ってないと、AI自体も理解ができない・精度も上がらない
- MCPの乱立による運用コスト増 → データ基盤1箇所と繋いでた方がコスパ良いのでは
- 全ツールに対してMCPの接続要件の調査や運用コストがかかること
- ツールとLLMの行き来の回数が増大し、LLMに対する input tokenがとんでも増大するのでは
データ基盤は、データが1箇所に集まっており・データガバナンスも効いており・データモデリングが整っている状態を作り出せますし、参照しやすく権限管理も一元化できるような運用を目指して改善することのできる場所です。
なので、データ基盤はMCP利用しLLMでデータ分析を実施する状況においても、非常に重要な役割を果たすと考えられます。
よって、データエンジニア業は必要な業務であり続けるのではないかと思います。
2.MCPによってデータと人が関わるインターフェイスは大きく変化
LLMがデータのすぐ近くにいるため、集計スキルを必要としないため多くの人がデータに触れるようになるでしょうし、インサイトを得るためのデータの探索やアドホック分析のあり方は多様化していくでしょう。おそらくAIを使うのがデファクトスタンダードになっていく気はしています。大きい変化だと思います。
一方、AIはハルシネーションやデータ構造の複雑怪奇さから集計を間違えることがあるので、データを扱う人のドメイン知識や分析スキル自体が大事であることに変わらないですし、「正確性を大きく求められる業務」などは引き続きAIではなく、何かしらの処理で行われていくのは変わらないのではと思います。
あとがき
今回はmcp-snowflake-serverを紹介させていただきました。
LLMでデータに触れる人の裾野が広がったからこその問題なども今後は予想されますが、またその時に…